Response to FIPA Call For Proposals
France Télécom - CNET
D. Sadek, P. Bretier, F. Panaget
France Télécom
CNET - DIH/RCP
Technopole Anticipa - 2, Avenue Pierre Marzin
22307 Lannion Cedex - France
E-mail: sadek@lannion.cnet.fr
Tel. : +33 2 96 05 31 31
Fax : +33 2 96 05 35 30
Submission for standardisation of components of
France Télécom's ARTIMIS technology
ARCOL agent communication language and
MCP, CAP and SAP agent's cooperativeness protocols
1. Introduction
2. What does ARTIMIS technology consist of and why does it fit
FIPA requirements?
3. Components of ARTIMIS technology submitted to standardisation
3.1. Interacgent Communication Language: ARCOL
3.1.1. Framework for ARCOL semantics: the SL language
3.1.1.1. Bases of the SL formalism
3.1.1.2. The Components of a Communicative Act Model
3.1.1.3. ARCOL's primitive communicative acts
3.1.2. Flexibility of the ARCOL language
3.2. Comparison with KQML
3.3. A few words about KIF compared to SCL
3.4. Agent Cooperativeness Protocols: MCP, CAP, SAP
3.4.1. Minimal Cooperativeness Protocol (MCP): A Basic
Interaction Protocol
3.4.2. The Corrective-Answers Protocols (CAP)
3.4.3. The Suggestive-Answers Protocol (SAP)
4. Why the components submitted to standardisation and ARTIMIS
technology are relevant to FIPA?
In this proposal, two components of ARTIMIS, an effective
generic intelligent agent technology developed by France Télecom,
are submitted for standardisation:
- an interagent communication language, ARCOL (ARtimis COmmunication Language), and,
- Three protocols for agent's cooperative reactions: MCP
(Minimal Cooperation Protocol), CAP (Corrective-Answers Protocol),
and SAP (Suggestive-Answers Protocol).
The whole ARTIMIS technology, in particular the submitted language and protocols, is available.
ARTIMIS is an agent technology which provides a generic
framework to instantiate intelligent dialoguing agents, which can interact
with human users as well as with other software agents. When
instantiated in a human-agent interaction context, ARTIMIS-like
agents can engage in mixed-initiative cooperative interaction in
natural language with human users. The resulting systems are able
to display advanced functionalities, such as negotiating the
user's requests, producing cooperative answers (which involves
relevant, possibly non explicitly requested information),
performing complex tasks, etc.
Primarily designed to support advanced interactive services
and to offer user-friendly cooperative intelligent interfaces to information
bases, ARTIMIS intelligent agent technology, de facto, strongly
relates to end-user applications.
Roughly speaking, the ARTIMIS software consists of three main
components [Sadek et al 96]: a rational unit (which constitutes
the heart of the technology), and two front-end components for
natural language processing: understanding and generation.
The rational unit is the decision kernel of the agent. It
endows the agent with the capability to reason about knowledge
and actions. It performs cooperative rational reaction calculus
producing motivated plans of actions, such as plans of speech acts. In
this framework, communicative acts are modelled as regular rational
actions, thus enabling the agent to handle interaction. The
communication protocols are dynamic and flexible: there is no
predetermined interagent interaction patterns.
The two natural language components [Sadek et al 96, Panaget
96] are essential to use the technology in a context of interaction
with humans. They bridge the gap between the communication
language (which, in this case, is natural language) and the
internal semantical knowledge representation in terms of communicative
acts with semantic contents expressed in a powerful language: a
first-order modal language.
Without the two natural language components, the rational
unit is an intelligent communicating agent (in a context of human-agent
interaction, the human user is viewed as a particular agent; no
assumption is made about the interlocutor's type). Therefore, the
rational unit can be used as a regular communicating agent in a
multi-agent system.
The ARTIMIS model is a formal theory of rational interaction
expressed in a homogeneous logical framework [Sadek 91a]. The
basic concepts of this framework are mental attitudes and
actions. The theory provides, in particular, a model for the relationships
between all the mental attitudes of an agent, principles of
rational behaviour, principles of cooperative behaviour, and
fine-grained models of communicative acts (and actions in
general). The set of the primitive communicative acts is small, but
the expressive power of the underlying language enables to handle
complex interaction, because the language allows for complex
combinations (e.g., sequences, alternatives) required by
the negotiation and coordination protocols used by the agents,
and for a high expressiveness of the message contents.
ARTIMIS involves a homogeneous set of generic logical
propertys, which embodies the innate potential of the system. This potential
is independent of its specific use in a given application domain.
The underlying technology is an inference engine [Bretier 95,
Bretier & Sadek 96] which faithfully executes the theory. The
ARTIMIS technology offers several advantages. Firstly, the
specification of ARTIMIS, i.e., the theory of rational
interaction, is semantically well-defined, and non ambiguous. Secondly,
it can be guaranteed that ARTIMIS follows its specifications
soundly and completely (e.g., keeps its commitments).
Thirdly, ARTIMIS can be easily maintained, adapted, and/or
customised.
So far, to our knowledge, there is no intelligent agent
technologies/products comparable to ARTIMIS.
ARTIMIS is implemented in Quintus Prolog on a Sun Ultra 1
under Solaris 2.5. It is a stand-alone software which is integrated
in a speech-telephony-computer platform (i.e., a speech
recognition software, a speech synthesis software and an ISDN
board/software). Currently, ARTIMIS is demonstrated on a lab
version of a real application, AGS, the directory of added-value
voice-activated services hosted by France Telecom (Audiotel services)
[Sadek et al 95, 96].
ARTIMIS technology has been developed to support advanced
services, and mainly Telecom (telephone, Internet, etc.) services
requiring cooperative interaction with human users. There are
tremendous obvious commercial interests in ARTIMIS-like
technology, notably specifically designed
"high-quality" user-friendly interactive services, and intelligent-service
development tools.
ARTIMIS fits FIPA requirements for three main reasons.
Firstly, the kernel of ARTIMIS, a rational unit, allows, in particular, dynamic
and flexible communication protocols. Secondly, ARTIMIS is based
on a semantically well-defined theory of communication and
cooperation. And thirdly, since ARTIMIS is based on a rational
unit, it allows an efficient combination of services without that
the plugging of a new service requires an explicit specification of
its relation with the other services.
Are submitted for standardisation, an interagent communication language, ARCOL, and three cooperative reaction protocols, MCP, CAP, and SAP.
An agent communication language allows to express messages.
Traditionally, Speech act theory is used as the basis for the definition
of messages. A message is specified as a communicative act type, e.g.,
a speech act type (also called communicative function), applied
to a semantic content (also called propositional content). The
semantic contents of communicative acts may be of three different
types, depending on the type of the communicative acts:
propositions, individuals, and communicative acts. It is worth
noting that the expressiveness of an interagent communication
language strongly depends on the expressiveness of the language
for semantic contents.
In our view, a communication language has to specify a set of
primitives from which any message can be built up. This view applies
both to the sub-language for the communicative functions and to
the language for semantic contents. For example, as regard the
former, one have to define, on one hand, basic communicative act
types, and, on the other hand, operators to combine these acts in
order to build complex messages.
As specified by FIPA requirements, our definition of the ARCOL interagent communication language is twofold:
(1) the definition of communicative acts (or basic message types), and
(2) the definition of the language, SCL, for the semantic
contents.
ARCOL involves the following primitive communicative acts
[Sadek 91b]:
act: < i, INFORM(j, p) >
meaning:
agent i informs agent j that proposition p is true,
performance conditions:
i believes that p,
i believes that j does not believes that p,
i has the intention that j comes to believe that p.
act: < i, REQUEST (j, a) >
meaning:
agent i requests agent j to perform action (e.g., comm. act) a,
performance conditions:
i believes that (as far as he is concerned) a is "performable",
i believes that j does not have the intention to do a.
i has the intention that j performs a.
act: < i, CONFIRM (j, p) >
meaning:
agent i confirms to agent j that proposition p is true,
performance conditions:
i believes that p,
i believes that j is uncertain about p,
i has the intention that j comes to believe that p.
act: < i, DISCONFIRM (j, p) >
meaning:
agent i disconfirms to agent j that p is true,
performance conditions:
i believes that p,
i believes that j is uncertain about p or believes that p,
i has the intention that j comes to believe that p.
act: < i, INFORMREF (j, ix d(x)) >
meaning:
agent i informs agent j of the value of the referent x denoted
by description d(x),
performance conditions:
i knows (or believes that he knows) the referent x of d(x),
i believes that j does not know the referent x of d(x),
i has the intention that j comes to know the
referent x of d(x).
where p is a proposition of SCL, a an action
expression (e.g., a communicative act), and x d(x) a term (denoting an object) described
by the description d(x), i.e.,
a proposition of SCL with a free variable x.
The semantics of the primitive communicative acts has to be
expressed in a language: SL,
(1) containing SCL, since the semantic contents appear in the semantic definitions of the communicative acts (preconditions and effects), and
(2) allowing for the expression of mental attitudes such as intentions and beliefs.
The expressiveness of ARCOL depends on the expressiveness of
SCL. For instance, if agents are intended to be able to inform
about their own beliefs or intentions, SCL must allow for the
expression of such mental attitudes.
In our view, SCL and SL has to be unified. Thus the whole
expressiveness of SL will be available for the expression of semantic
contents.
SL being the language for ARCOL semantics, it has to be precisely defined. In this section, we present the SL language definition and the semantics of the ARCOL primitive communicative acts.
Propositions are expressed in a logic of mentale attitudes and actions, formalised in a first order modal language with identity, similar in many aspects to that of Cohen & Levesque (1990b). (See [Sadek 91] for details of this logic.) Let us briefly sketch the part of the formalism used in this proposal. In the following, p, p1, ... are taken to be closed formulas (denoting propositions), and formula schemas, and i and j are schematic variables which denote agents. means that is valid. The mental model of an agent is based on the representation of three primitive attitudes: belief, uncertainty and choice (or, to some extent, goal). They are respectively formalized by the modal operators B, U and C. Formulas as Bip, Uip and Cip can be read, respectively, "i (implicitly) believes (that) p", "i thinks that p is more likely than its contrary" and "i desires that p currently holds". The logical model for the operator B is a KD45 possible-worlds semantical Kripke structure (see, e.g., [Halpern & Moses 85]) with the fixed domain principle (see, e.g., [Garson 84]). To enable reasoning about action, the universe of discourse involves, in addition to individual objects and agents, sequences of events. A sequence may be formed by a single event. This event may be also the void event. The language involves terms (in particular a variable e) ranging over the set of event sequences. To talk about complex "plans", events (or actions) can be combined to form action expressions, such as sequences a1;a2 or nondeterministic choices a1a2. Action expressions will be noted a. The operators Feasible, Done and Agent are introduced to enable reasoning about actions. Formulas Feasible(a,p), Done(a,p) and Agent(i,a) respectively mean that a can take place and if it does p will be true after that, a has just taken place and p was true before that, and i denotes the only agent of the events appearing in action expression a.
From belief, choice and events, the concept of persistent goal is defined. An agent i has p as a persistent goal, if i has p as a goal and is self-committed toward this goal until i comes to believe that the goal is achieved or to believe that it is unachievable. Intention is defined as a persistent goal imposing the agent to act. Formulas as PGip and Iip are intended to mean that "i has p as a persistent goal" and "i has the intention to bring about p", respectively. The definition of I entails that intention generates a planning process.
A fundamental property of the proposed logic is that the modelled agents are perfectly in coherence with their own mental attitudes. Formally, the following schema is valid:
Bi
where is governed by a modal operator formalizing a mental attitude of agent i.
Below, the following abbreviations are used:
Feasible(a) Feasible(a,True)
Done(a) Done(a,True)
Possible() (e)Feasible(e,)
Bifi Bi Bi
Brefi(x) (y)Bi(x)(x)=y
Uifi Ui Ui
Urefi(x) (y)Ui(x)(x)=y
ABn,i,j BiBjBi....
In the fifth and seventh abbreviations, is the operator for definite description; (x)(x) is read "the (x which is) ". In the last one, which introduces the concept of alternate beliefs, n is a positive integer representing the number of B operators alternated between i and j.
The components of a Communicative Act (CA) model that are involved in a planning process characterize both the reason for which the act is "selected" and, the conditions that have to be satisfied for the act to be planned. For a given act, the former is referred to as the rational effect (RE) (sometimes also referred to as the perlocutionary effect), and the latter are the feasibility preconditions (FPs) (or qualifications).
To give an agent the capability of planning an act whenever the agent intends to achieve its RE, the following property is proposed:
Property 1: Let ak be an act such that:
(x) Biak=x,
p is the RE of ak and
Ci Possible(Done(ak));
then the following formula is valid: Iip IiDone(a1...an)
where a1, ...,an are all the acts of type ak.
This Property says that for an agent the intention to achieve a given goal generates the intention that be done one of the acts know to the agent and which are such that their RE corresponds to the agent's goal and the agent has no reason for not doing them.
The set of feasibility preconditions for a CA can be split into two subsets: the ability preconditions and the context-relevance preconditions. The ability preconditions characterize the intrinsic ability of an agent to perform a given CA. For instance, to sincerely Assert some proposition p, an agent has to believe p. The context-relevance preconditions characterize the relevance of the act to the context in which it is performed. For instance, an agent can be intrinsically able to make a promise while believing that the promised action is not needed by the addressee. The context-relevance preconditions may correspond to the Gricean quantity and relation maxims.
The following property imposes on an agent, whenever the agent "selects" an act (in virtue of Property 1), to seek the satisfiability of its FPs:
Property 2: IiDone(a) BiFeasible(a) IiBiFeasible(a)
An agent cannot intend to perform (the illocutionary component
of) a communicative act for a different reason from the act's RE.
The following property formalizes this idea:
Property 3: IiDone(a) IiRE(a), where RE(a) is the RE of act a.
Consider now the opposite aspect: the consommation of CAs. When an agent observes a CA, he has to come to believe that the agent performing the act has the intention (to make public his intention) to achieve the act's RE. This kind of the act effect is called the intentionnal effect. The following captures this consideration:
Property 4: Bi(Done(a) Agent(j, a) IjRE(a))
There are FPs that persist after an act. For the particular case of CAs, this is the case for all the FPs which do not refer to time. Then, when an agent observes a CA, he has to come to believe that the persistent FPs hold:
Property 5: Bi(Done(a) FP(a))
Hereafter, a CA model will be presented as follows:
< i, Act (j, ) >
FP: 1
RE: 2
where i is the agent of the act, j the addressee, Act the name of the act, its semantic content (or propositional content) (SC), 1 its FPs and 2 its RE.
The assertive Inform:
One of the most interesting assertives regarding the core of mental attitudes it encapsulates (or we want it to encapsulate) is the act of Informing. An agent i is able to Inform an agent j that some property p is true only if he/she believes p (i.e., only if Bip). This act is considered to be context-relevant only if i does not think that j already believes p (i.e., only if BiBjp).
Given the core of mental attitudes just highlighted for the act Inform, we propose a first model for this act as follows; this model will be adapted to the other acts we will introduce later, with the aim of keeping the acts qualifications mutually exclusive (when the acts have the same effect):
< i, INFORM (j, ) >
FP: Bi BiBj
RE: Bj
The Directive Request:
We propose the following model for the directive Request, a being a schematic variable for which can be substituted any action expression, FP(a) being the feasibility precondition of a, and FP(a) [i\j] being the FPs of a concerning the mental attitudes of agent i:
< i, REQUEST (j, a) >
FP: FP(a) [i\j] BiAgent(j,a) BiPGjDone(a)
RE: Done(a)
The Confirmation:
First of all, let us mention that the rational effect of the act Confirm is identical to that of most of the assertives, i.e., the addressee comes to believe the SC of the act. An agent i is able to Confirm a property p to an agent j only if i believes p (i.e., Bip). This is the sincerity condition an assertive imposes on its agent. The act Confirm is context-relevant only if i belives that j is uncertain about p (i.e., BiUjp). In addition, the analysis we have performed in order to determine the necessary qualifications for an agent to be justified to claim the legitimacy of an act Inform remains valid for the case of the act Confirm. These qualifications are identical to those of an act Inform for the part concerning the ability, but they are different for the part concerning the context relevance. Indeed, an act Confirm is irrelevant if its agent believes that the addressee is not uncertain of the property intended to be Confirmed.
In virtue of this analysis, for the act Confirm we propose the following model:
< i, CONFIRM (j, ) >
FP: Bi BiUj
RE: Bj
The act Confirm has a negative "counterpart": the act Disconfirm. The characterization of this act is similar to that of the act Confirm and leads us to provide the following model:
< i, DISCONFIRM (j, ) >
FP: Bi Bi(Uj Bj)
RE: Bj
Redefining the Act Inform: Mutual Exclusiveness Between Acts:
The qualifications of the act Inform have to be reconsidered according to the models of the acts Confirm and Disconfirm such that the context relevance be total (i.e., such that the preconditions of the three act models be mutually exclusive). To do that, it is sufficient to formalize the following property (and its "complementary"): to be justified to Inform, an agent must not be justified either to Confirm (and hence to believe that the addressee is uncertain of the SC of the act) or to Disconfirm (and hence to believe that the addressee is uncertain of, or believes the contrary of the SC of the act). The updated model for the act Inform is the following one:
< i, INFORM (j, ) >
FP: Bi Bi(Bifj Uifj)
RE: Bj
Hence, in a given context, among several acts which
(potentially) achieve some goal, there is at most one act, the preconditions
of which are satisfied. This means that the agent can never be
faced with two illocutionary acts leading to the same situation,
both of them being context-relevant.
The Closed-Question Case:
In terms of Illocutionary Acts (IAs), exactly what a speaker i is Requesting when uttering a sentence such as "Is p?" to a hearer j, is that j performs the act "Inform i that p" or performs the act "Inform i that p". We know the model of both of these acts: < j, INFORM (i, ) >. In addition, we know the relation "or" set between these two acts: it is the relation that allows the building of action expressions which represent a nondeterministic choice between several (sequences of) events.
In fact, as mentioned above, the semantic content of a directive refers to an action expression; so, this can be a disjunction between two or more acts. Hence, by using the utterance "Is p?", what an agent i Requests an agent j to do is the following action expression:
< j, INFORM (i, p) > < j, INFORM (i, p) >
Now, it seems clear that the SC of a directive realized by a yn-question can be seen as an action expression characterizing an indefinite choice between two IAs Inform. In fact, it can also be shown that the binary character of this relation is only a special case: in general, any number of IAs Inform can be handled. In this case, the addressee of the directive is allowed to "choose" one from among several acts. This is not only a theoretical generalization: it accounts for some ordinary linguistic behaviour traditionally called Alternatives question. An example of an utterance realizing this type of act is "Would you like to travel in first, second or third class ?". In this case, the SC of the Request realized by this utterance is the following action expression:
< j, INFORM (i, p1 ) > < j, INFORM (i, p2 ) > < j, INFORM (i, p3) >
where p1, p2 and p3 are intended to mean respectively that j wants to travel in first class, in second class, or in third class.
Now, we have to provide the plan-oriented model for this type of action expression. In fact, it would be interesting to have a model which is not specific to the action expressions characterizing the nondeterministic choice between IAs of type Inform, but a more general model where the actions referred to in the disjunctive relation remain unspecified. In other words, we would like to describe the preconditions and effects of the expression a1 a2 ... an where a1, a2,..., an are any action expressions. It is worth mentioning here that we want to characterize this action expression when it can be planned as a disjunctive macro-act. We are not attempting to characterize the nondeterministic choice between acts which are planned separately. In both cases, we get a branching plan but in the first case, the plan is branching in an a priori way while in the second case it is branching in an a posteriori way.
An agent will plan a macro-act of nondeterministic choice when she intends to achieve the RE of one of the acts compounding the choice, no matter which one it is. To do that, one of the feasibility preconditions of the acts must be satisfied, no matter which one it is. Therefore, we propose the following model for a disjunctive macro-act:
a1 a2 ... an
FP: FP(a1) FP(a2) ... FP(an)
RE: RE(a1) RE(a2) ... RE(an)
where FP(ak) and RE(ak) represent respectively the FPs and the RE of the action expression ak.
<i,INFORM(j,)> <i,INFORM(j,)>
FP: Bifi Bi(Bifj Uifj)
RE: Bifj
In the same way, we can derive the disjunctive macro-act model which gathers together the acts Confirm and Disconfirm. We will hereafter use the abbreviation < i, CONFDISCONF (j, ) > to refer to the following model:
<i,CONFIRM(j,f)> | <i,DISCONFIRM(j,f)>
FP: Bifif BiUjf
RE: Bifj
The Strict-Yn-Question Act Model:
Starting from the act models < j, INFORMIF (i, f) > and < i, REQUEST (j, a) >, we build up the strict-yn-question act (and not plan, as seen below) model. Unlike a Confirm/Disconfirm-question, which will be addressed below, a strict-yn-question requires from its agent not to have any "knowledge" about the proposition the truth value of which is asked for. To get the intended model, a transformation must be applied to the FPs of the act < j, INFORMIF (i, f) >. In accordance with this proposition, we get the following model for a strict-yn-question act:
< i, REQUEST (j, < j, INFORMIF (i, f) >) >
FP: Bifif Uifif BiPGjDone(< j, INFORMIF (i, f) >)
RE: Done(< j, INFORM (i, f) > | < j, INFORM (i, f) >)
The Confirm/Disconfirm-question Act Model:
In the same way, we can derive the following Confirm/Disconfirm-question act model:
< i, REQUEST (j, < j, CONFDISCONF (i, f) >) >
FP: Uif BiPGjDone(< j, CONFDISCONF (i, f) >)
RE: Done(< j, CONFIRM (i, f) > | < j, DISCONFIRM (i, f) >)
The Open-Question Case
Open question is a question which is not closed, i.e., which does not suggest a choice and, in particular, which does not require a yn-answer. A particular case of open questions are the questions which require a referring expression as an answer. They are generally termed wh-questions. The "wh" refers to the interrogative pronouns such as "what", "who", "where", or "when". Nevertheless, this must not be taken literally since the utterance "How did you travel ?" can be considered as a wh-question.
Now, we are interested in setting up a formal plan-oriented model for the wh-questions. In our opinion, from the addressee point of view, this type of question can be seen as a closed question where the suggested choice is not made explicit because it is "too wide". Indeed, a question such as "What's your destination ?" can be restated as "What's your destination: Paris, Rome,... ?".
When asking a wh-question, an agent j intends to acquire from the addressee i an identifying referring expression (IRE) [Sadek 90] for (generally) a definite description. So, the agent j intends to make his interlocutor i perform an IA of the following form:
< i, INFORM (j, ix d(x) = r) >
where r is an IRE (e.g., a standard name or a definite description) and ix d(x) is a definite description. Hence, the SC of the directive performed by a wh-question is a disjunctive macro-act compounded with acts of the form of the one above. Here is the model of such a macro-act:
< i, INFORM (j, ix d(x) = r1) > ... < i, INFORM (j, ix d(x) = rk) >
where rk are IREs. To deal with the case of closed questions, the plan-oriented generic model we have proposed for a disjunctive macro-act can be instantiated here for the account of the macro-act above. Note that the following equivalence is valid:
(Bi ixd(x) = r1 Bi ixd(x) = r2 ... ) (y)Bix(x) = y
we propose the following model, which we will refer to as < i, INFORMREF (j, ix d(x)) >:
< j, INFORMREF (i, ix d(x)) >
FP: Brefid(x)) Birefjd(x)
RE: Brefjd(x)
where refjd(x), Brefjd(x) and Urefjd(x) are the three following abbreviation schemas:
refjd(x) Brefjd(x) Urefjd(x)
Brefjd(x) (y)Bixd(x)=y
Urefjd(x) (y)Uixd(x)=y
Now, provided the act models < j, INFORMREF (i, ix d(x)) > and < i, REQUEST (j, a) >, the wh-question act model can be built in the same way we have done in the case of the yn-question act models. Applying the transformation to the FPs of the act schema < j, INFORMREF (i, ixd(x)) > and by virtue of proposition 3, we get the following model:
< i, REQUEST (j, < j, INFORMREF (i, ix d(x) >) >
FP: refid(x) BiPGjDone(< j, INFORMREF (i, ixd(x)) >)
RE: Done(< i, INFORM (j, ixd(x)=r1)
>|...< i, INFORM (j, ixd(x)=rk)>)
Building Interagent Communication Plans:
The properties of rational behaviour we have stated when we have defined the RE and the FPs of a CA specify an algorithm of CA planning. This algorithm builds a plan through the inference of the causal chain of intentions, resulting from the application of properties 1 and 2.
With this method, it can be shown that what is usually called "dialogue acts" and their models which are postulated, are, in fact, complex plans of interaction, and so can be derived from elementary acts using the principles of rational behaviour. Let us see an examplesof how this is done.
The interaction plan "hidden" behind a question act can be more-or-less complex depending on the agent mental state when the plan is generate.
Let us call direct question a question undelain by a plan limited to the reaction strictly legitimized by the question. Suppose that (the base of) i's mental state is:
BiBifjf, Ii,Bifif
In virtue of property 1, the intention that the act < j, INFORMIF (i, f) > be done is generated. Then, according to property 2, follows the intention to bring about the feasibility of this act. So, the problem is to know whether the following belief can be derived at this moment (from i's mental state):
Bi(Bifjf (BjBifif Uifif))
This is the case with i's mental state. By virtue of properties 1 and 2, the intention that the act < i, REQUEST (j, < j, INFORMIF (i, f) >) > be done and then the intention to achieve its feasability, are inferred. The following belief is derivable:
Bi(Bifif Uifif)
Now, no intention can be inferred. This terminates the
planning process. The performance of a direct strict-yn-question plan can
be started for instance by uttering a sentence such as "Has
the flight from Paris arrived ?"
Given the FPs and the RE of the plan above, the following model for a direct strict-yn-question plan can be derived:
<i,YNQUESTION(j,f)>
FP: BiBifjf Bifif Uifif BiBj(Bifif Uifif)
RE: Bifif
When unified to SL, SCL (the language for semantic content)
happens to be a rich language but may turn out to be difficult to use
as such (nevertheless, it is worth recalling that the required
technology, ARTIMIS, to use it is available now). However, as
mentioned above, ARCOL expressiveness is conditioned by SCL one.
Suppose that one want to simplify SCL, for example by
restricting it to a first-order predicate logic language. Let us
call this simplified version SCL1. In this case, ARCOL is
accordingly restricted also to a language ARCOL1. Yet, we would like
to enable the agents to communicate their mental attitudes
(beliefs, intentions, etc.). One solution is to augment
the set of ARCOL1's communicative acts with complex acts (namely,
macro-acts) which intrinsically integrate in their semantics relevant
mental attitudes. For example, the act of agent i informing
agent j that it (i.e., i) has a given
intention, has the following semantics in ARCOL:
< i, INFORM (j, Iip) >:
FP: Iip BiBjIip BiBjIip
ER: Bjp
This act can be defined in ARCOL1 as follows:
< i, INFORM-I (j, p) >:
FP: Iip BiBjIip BiBjIip
ER: BjIip
Of course, this ARCOL1's new act < i, INFORM-I
(j, p1) > is only an abbreviated form
of < i, INFORM (j, Iip) >
of ARCOL since propositions p and p' are expressen
in SCL and SCL1, respectively.
In other respects, the major downside of this solution is that
it requires the definition of an additional communicative act each time
the semantic content cannot be expressed in the first-order
predicate language.
In any case, agents are required to express communicative acts
which refer to mental attitudes, the corresponding technology must
enable the manipulation of such notions. Subsequently, if agents
have these notions explicitly represented in their own kernels,
there no a priori reason not to include them into the agent communication
language.
One of the interagent communication languages that have been
proposed recently seems to emerge: KQML [KQML93,LF94,FLM96]. KQML
has been designed to facilitate high-level cooperation and
interoperation among artificial agents. Agents may range from
simple programs and databases to more sophisticated
knowledge-based systems. In KQML, agents communicate by passing
so-called "performatives" to each other. KQML provides
an open-ended set of "performatives", whose meaning is
independent of the propositional content languages (e.g.,
first-order logic, SQL, Prolog, etc.). Examples include
ACHIEVE, ASK-ALL, ASK-IF, BROKER, DELETE-ALL, DENY, STREAM-ALL, TELL, UNTELL,
UNACHIEVE. Moreover, KQML provides a set of conversation policies
that expresses which "performatives" start a
conversation and which "performatives" are to be used
at any given point of a conversation. These policies induce a set of
interagent conversation patterns using the communication actions.
Several general difficulties with the KQML specification have been identified. The major one is that the meaning of the defined "performatives" is rather unclear. "Performatives" are given in English glosses, which often are vague and ambiguous (a first attempt to clarify the language has been made [LF94], but much work remains). For example, the "performative" DENY is defined as follows [KQML93, p. 12]:
DENY
:content <performative>
:language KQML
:ontology <word>
:in-reply-to <expression>
:sender <word>
:receiver <word>
"Performatives" of this type indicate that the
meaning of the embedded <performative> is not true of the
sender. A deny of a deny cancels out.
As noted by Cohen & Levesque [CL95], if an agent denies a tell,
does that mean that the agent did not tell earlier, or does not
believe what is being said now? Cohen & Levesque highlighted
another confusion: the DENY act says that what agents deny is a
performative, and that it is no longer true of the speaker. This
implies that "performatives" do in fact have truth values,
and are not actions after all. And, given that other
"performatives" are defined in terms of DENY, such as UNACHIEVE,
UNREGISTER and UNTELL, it is not a small problem.
Another example of vagueness appears with the
"performative" DELETE-ALL which is defined as follows
[KQML93, p. 17]:
DELETE-ALL
:content <expression>
...
"Performatives" of this type indicate that sender
want the receiver to remove all sentences that match
<expression> in its virtual knowledge base.
First of all, if the notion of believe (or knowledge) is
meaningful for an agent, it is not clear what does removing propositions mean
exactly? Does it mean believing the opposite propositions?
becoming ignorant about the referred propositions? Secondly, how
can the "ALL" be circumscribed? If all an agent's knowledge,
including its reasoning rules, is "coded" in the same
knowledge base, and that the agent receives the
"performative" DELETE-ALL with a content that matches
everything, the agent should, a priori, remove all its
knowledge base. Thirdly, a matching operation must be defined for
each propositional content language. For example, if the language
is Prolog, we can suppose that "matching" means
"unification". But, what does "matching" mean
when the language is the first-order logic? Therefore, the
meaning of the DELETE-ALL act depends on the meaning of the
matching operation. Thus, any attempt to semantically define KQML's
performatives requires beforehand to have a complete and clear
semantics for the language of communicative act contents. This also
applies to the EVALUATE "performatives" and its
variants such as ASK-IF, ASK-ALL, and STREAM-ALL:
EVALUATE
:content <expression>
...
"Performatives" of this type indicate that the
sender would like the recipient to simplify <expression>,
and reply with this result. (Simplification is a language specific
concept, but it should subsume "believed equal".)
[KQML93, p. 15]
We consider that simplification is more than a
language-specific concept: it is a domain- specific operation.
For example, assuming that the propositional content language is
an arithmetic language, the simplification of an expression such
as "1x2x4" can be "8", "2x2x2"
(prime numbers), or any other relevant expression.
In fact, there are only two types of speech acts that are
hidden into the English glosses of each KQML's
"performatives": directives and assertives. In particular,
although KQML is extensible, an important class of speech acts
seems to be missing: the commissives, such as promising,
accepting a proposal, agreeing to perform a requested action,
etc. And, it is hard to see how agents can robustly communicate
without these actions or a way to express commissive attitudes,
such as intentions (see, e.g., the ARCOL1's Inform-I
communicative act).
Is it relevant for the high-level communication language KQML
to define "performatives" such as STANDBY, READY and NEXT
which are useful to deal with the low-level problem of buffering
stream? In the same way, KQML defines several families of
"performatives" that differ according to the format of
the expected replies. For example, STREAM-ALL is like ASK-ALL
except that rather replying with a "performative"
containing a collection of solution, the responder sends series
of "performatives", each of them containing a member of
that collection.
ARCOL has no one of the troubles or weaknesses mentioned.
Moreover, it can provide the same (and much more) expressive
power as KQML's, starting from a smaller set of semantically
well-defined primitive communicative acts. If needed, more
complex and/or specific (or customised) acts can be easily defined
with the same precise semantics.
For example, the two KQML's "performatives" TELL
(which indicates that its content is in the sender's virtual
knowledge base), and INSERT (which indicates that its content
must be added to the receiver's virtual knowledge base) are respectively expressed
in ARCOL with the same communicative act as follows:
< i, INFORM (j, Bip) >
and
< i, INFORM (j, IiBjp) >
KIF [Genesereth & Fikes 92] is a knowledge representation language which may be compared to SCL. Unlike SCL, which is not related to any programming language, KIF is strongly LISP-oriented: whatever the interpretation language mechanism is, it must handle, at least, the quotation and the comma, and potentially the whole LISP language. Moreover, unlike ARTIMIS's automated inference unit, the existing inference engines for KIF (such as EPILOG and PROLOGIC) are rather weak regarding the intended richness of the language: firstly, apparently, deduction is limited to Horn clauses. Secondly, it is not clear how is inference drawn into the scope of the quotation operator, and especially into the scope of a belief operator. More generally, it is not clear at all how specific belief logics, particularly those relevant in the context of agent interaction , as KD45, or other BDI logics, can be handled
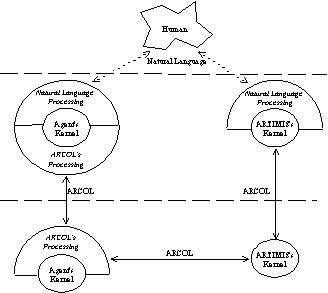
The strong overlap between human-agent interaction and
agent-agent interaction leads to design a common technology for these
two types of interaction.
Concerning the interaction protocols, a same argument can be
used. Agent-agent protocols are implemented through message
exchanges (i.e., speech acts or communicative acts). In
the case of human-agent interaction (and more specifically in natural
language interaction), the protocols are subject to a large variability
and do not correspond to a pre-specified script. At each step of
interaction, agents and humans react (ideally, in a rational way)
opportunistically according to the messages their receive. In the
case of agent-agent interaction, the protocols can (and, why
not?, should) also have the same flexibility.
The interaction protocols we propose are not relative to the interaction structure (e.g., an interaction grammar or automaton, as it is the case for the Contract Net protocol, for example), but rather to the agent's cooperative behaviour. In that sense, these protocols can be viewed as the basis for interagent negotiation.
The interagent interaction protocols make the agents committed
to basic behaviour principles which some of them directly follow
from the semantics of the communication language. As far as we
are concerned, given the ARCOL communication language defined in
section xxx (and considering that the agents follow its
semantics), a minimal cooperativeness is necessary and sufficient
for interaction to take place. Conversely, a minimal
cooperativeness is required for communication to be possible. For
example, suppose that agent A1 asks agent A2 if proposition p
is true; if both agents respect the semantics of the communication
language, A2 knows that A1 intends to know if p is true.
But, without a minimum of cooperativeness, A2 is in no way
constrained to react to A1's request.
Informally, the MCP protocol states that agents must not only
react when addressed but, more than that, they must adopt the interlocutor's
intention whenever they recognise it (if there is no objection to
adopt it). Formally, this principle is expressed as follows
[Sadek 91a]:
BiIj
IiBj IiBj
Actually, this protocol has a wide scope: it may produce cooperative behaviours which are much more complex than merely answering questions, such as making an agent forward a request to a competent agent if it cannot answer the request by itself (cf. brokering).
More complex cooperativeness protocols can also be
standardised.
Let us take an example with a Personal Travel Assistant (PTA).
A user wants to reserve a hotel room. She asks her PTA to find a
double room for her, with a bath-tub, a satellite-TV, for less
than 300 FF, for date d, and if not possible, to accept,
in priority, that the satellite-TV be replaced with regular-TV or
with no TV at all, or that the bath-tub be replaced with a shower or
with a shared shower. Finally, the user asks the PTA to contact
her if only rooms with higher prices are available.
The PTA contacts a hotel reservation agent and asks for a
double room with a bath-tub, a satellite-TV, for less than 300 FF, for
date d. Suppose that the rooms available on date d
are as follows:
| beds | bathroom | TV | Price |
| 1 double | bath-tub | reg-TV | 450 |
| 1 double | shower | sat-TV | 450 |
| 1 double | shared shower | - | 350 |
| 2 single | shared shower | reg-TV | 350 |
| 1 single | shared shower | - | 250 |
Without any cooperativeness protocol, the hotel reservation
agent would answer "0" (i.e., no room of the
requested type is available), and the PTA can infer no further
information from this answer, and would be led to ask further
questions (up to 9, i.e., (sat-TV, reg-TV, no
TV) = 3 x (bath-tub, shower, shared shower) = 3),
to which the hotel reservation agent may answer "0"
again.
But, with a cooperativeness protocol, by providing some
additional relevant information, the hotel reservation agent can enable
the PTA to use its inferential capabilities. For example, if the
hotel reservation agent has declared using a Corrective-Answers
Protocol (CAP) and produces the following answer: "There
are no double rooms neither for less than 300 FF, nor with a
bath-tub and a satellite-TV", the PTA can infer, on one
hand, all the answers to the new questions just mentioned, and,
on the other hand, that there are double rooms for more than 300
FF, double rooms with bath-tub, and double rooms with satellite-TV.
Such protocols are very useful for the efficiency of
interaction: not only they reduce the number of the exchanged
messages in an interaction, but also enable agents to optimally
exploit the messages they receive depending on their inferential abilities. However,
since these protocols cannot be necessarily made available for
all agents, they can be considered as complementary protocols
(unlike MCP which is intended to be a basic one) to which agents
may or may not subscribe. In this way, if an agent declares that
it is behaving according to these complementary protocols, its
interlocutors are entitled to infer certain type of relevant
information for its responses.
Of course, for an agent, to declare using a cooperativeness
protocol, as CAP for example, means to have certain inferential capabilities
and to commit to certain behaviour.
The second cooperativeness protocol we propose for
standardisation is the CAP protocol. First of all, we propose to standardise
the corrective-answers production principle. Formally,
this principle can be expressed as follows [Sadek 91a]:
Bi( Bj
Comp(i, )) IiBj
It says that an agent i will act to correct a statement believed
by another agent j whenever i thinks that it is
competent about the truth of and believes the opposite statement
.
By itself, this principle is not sufficient to support a CAP
protocol. Indeed, according to the inferential abilities of the so-called corrective agents
(i.e., using the corrective-answers production principle,
they will not detect the same sub-parts of a request which have
to be corrected. Since the CAP protocol is not intended to be
used by all the agents, a minimum of (reasonable and relevant)
inferential capabilities are required to be able to use it.
Thus, the corrective-answers production principle is augmented
with some minimal inferential capabilities. First of all, it seems necessary
that a corrective agent be able to infer that the persistent
qualifications of the communicative act it has just observed
hold. This condition is in complete conformity with the communication
language.
Secondly, some inferences about the object descriptions
mentioned in the request seem to be necessary too: for instance, provided
that a primitive request can be viewed at a certain level of
analysis as about an objet described with a conjunction of constraints
or object descriptions, the addressee must be able to infer that
the requesting agent believes that the described object exists
and that all the objects described by the sub-conjunctions of the
initial conjunction (namely, 2n object descriptions if
the request involves n constraints) also exist. For example, if
the request is about rooms with double bed and shower, the objects
described by the sub-conjunctions are rooms, rooms with double
bed, rooms with shower, and rooms with double bed and shower.
Moreover, the corrective answer must contain all the
problematical "minimal objects", i.e., the
minimal sub-conjunctions which cause the failure of the initial request.
To summarise, the CAP protocol submitted to standardisation involves:
- the correction principle (i.e., the commitment for an agent to be corrective and, consequently, to act in the case of opposite viewpoints) ;
- the mechanisms for inferring sub-conjunctions, in particular inferring all the problematical minimal sub-conjunctions.
One can go further concerning the production of cooperative
answers. In the previous example, the hotel reservation agent can
use a SAP protocol (in addition to the CAP protocol) to produce
the following answer to the first question of the PTA: « There
is neither double room for less 300 FF, nor with a bath-tub and
satellite-TV. But there are two double rooms for 450 FF each: one
with bath-tub and regular-TV, and the other with shower and satellite-TV. ».
This answer allows the PTA to infer (in addition to the
information given explicitly) that there is no double room
neither with bath-tub nor with satellite-TV, for less than 450
FF.
The SAP relies on a suggestive-answers production principle.
This principle consists in informing the requesting agent of other
possibilities when no strict answer to the request as it is
formulated. A standard way to determine these possibilities relies
on the standard determination of the corrective answers and on
the existence of universal metrics, i.e., metrics over dimensions
such as time, space, money, etc. The algorithm is as follows:
having explored the set of objects which are described by the
sub-conjunctions, the requested agent can identify a maximal
(with respect to the number of constraints appearing in the initial
request) non-problematical subset. A suggestive answer consists
in informing the requesting agent about (the existence of) a (set
of) particular object(s), by substituting, on a dimension having
a universal metrics, a new constraint (the closest one with
respect to the metrics) to the initial one.
On the previous example, the set of non-problematical objects
which has a maximal description can be the double rooms with
bath-tub or with satellite-TV, and the problematical constraint
having a universal metrics is the price. Thus, the hotel reservation
agent can suggest a double room with bath-tub for 450 FF and a
double room with satellite-TV for 450 FF.
As for the corrective-answers production principle and the
subsequent CAP protocol, all the agents are not intended to adopt
the suggestive-answers production principle or the SAP protocol.
To summarise, the SAP protocol submitted to standardisation involves:
- the suggestive-answers production principle (i.e., the commitment for an agent to be suggestive when possible) ;
- the mechanisms for the inference of maximal non-problematical sub-conjunctions and constraint substitution over universal metrics ;
ARCOL is a semantically well-defined, highly expressive,
adaptable, supported by an available intelligent agent technology (ARTIMIS),
interagent communication language. The expressive power of ARCOL
(and SCL) provides an accurate specification of the user's
personal preferences (or profile). ARCOL (and the underlying
ARTIMIS technology) does not induce any interagent conversational
patterns. Thus, an agent unsing ARCOL can display very flexible
interaction behavior (in particular, in the context of
human-agent interaction).
The protocols proposed are clearly specified. They provide a
very appropriate framework for efficient cooperative negotiation.
Indeed, they not only enable agents (and human users) to infer
relevant information from the received answers, but they also
allow to strongly minimise the number of required exhanges between
agents.
ARTIMIS interacts in ARCOL and follows the proposed
cooperativeness protocols proposed. For instance, ARTIMIS is able
to produce cooperative answers (corrective, suggestive, and other
types of cooperative answers). Moreover, since ARTIMIS is based
on an explicit first-order modal reasoning process, its
communicative and cooperative behaviour is specified
declaratively, in terms of logical properties, which are
implemented as such. To change its behaviour only require to modify
this set of logical properties. No translation from logics to
another language is required.
Since ARTIMIS involves a reasoning unit and is so able to draw
inferences, it can really combine services without that
the service provider (or designer) has to specify beforehand all
the relevant combinations. In that sense, ARTIMIS fits a plug-and-play
architecture that is required for the FIPA target applications.
Finally, the reasoning abilities of ARTIMIS are useful to deal
with the notion of "semantically-related-to" which is particularly relevant
during for the dertermination of cooperative answers, and the
filtering and retrieval of relevant information (particularly
required for applications such as Personal Assistant, Personal
Travel Assistant, and Audio-Visual Entertainment and
Broadcasting). Such abilities are more important especially when
the application has a wide semantic domain (as, for example,
Audio-Visual Entertainment and Broadcasting).
[Bretier 95] Bretier P. La communication orale coopérative : contribution à la modélisation logique et à la mise en oeuvre d'un agent rationnel dialoguant. Thèse de Doctorat Informatique, Université de Paris XIII, 1995.
[Bretier & Sadek 96] Bretier P. & Sadek M.D. A rational agent as the kernel of a cooperative spoken dialogue system: Implementing a logical theory of interaction. Proceedings of the ECAI'96 workshop on Agent Theories, Architectures, and Languages (ATAL), Budapest, Hungry, 1996. (A paraître).
[Cohen & Levesque 90] Cohen P.R. & Levesque H.J. Intention is choice with commitment. Artificial Intelligence, 42(2-3):213--262, 1990.
[Cohen & Levesque 95] Cohen P.R. & Levesque H.J. Communicative actions for artificial agents; Proceedings of the First International Conference on Multi-agent Systems (ICMAS'95), San Francisco, CA, 1995.
[Finin et al 96] Finin T., Labrou Y. & Mayfiled J., KQML as an agent communication language, Bradshaw J. ed., Sofware agents, MIT Press, Cambridge, 1996.
[Genesereth & Fikes 92] Genesereth M.R. & Fikes R.E. Knowledge interchange format. Technical report Logic-92-1, CS Department, Stanford University, 1992.
[Guyomard & Siroux 89] Guyomard M. & Siroux J. Suggestive and corrective answers : A single mechanism. In Taylor M.M., Néel F., & Bouwhuis D.G., editors, The structure of multimodal dialogue, North-Holland, 1989.
[Garson 84] Garson, G.W. Quantification in modal logic. In Gabbay, D., & Guentner, F. eds. Handbook of philosophical logic, Volume II: Extensions of classical Logic. D. Reidel Publishing Company: 249-307. 1984.
[Halpern & Moses 85] Halpern, J.Y., & Moses Y. A guide to the modal logics of knowledge and belief: a preliminary draft. In: Proceedings IJCAI-85, Los Angeles, CA. 1985.
[Kaplan 82] Kaplan S.J. Cooperative responses from a protable natural language query system. Artificial Intelligence, 19:165--187, 1982.
[KQML93] External Interfaces Working Group, Specification of the KQML agent-communication language, 1993.
[Labrou & Finin 94] Labrou Y. & Finin T., A semantic approach for KQML - A general purpose communication language for software agents, Proc. of 3rd International Conference on Information Knowledge Managment, November 1994.
[Panaget 96] Panaget F. D'un système générique de génération d'énoncés en contexte de dialogue oral à la formalisation logique des capacités linguistiques d'un agent rationnel dialoguant. Thèse de Doctorat Informatique, Université de Rennes I, 1996.
[Sadek 90] Sadek M.D., Logical task modelling for Man-machine dialogue. Proceedings of AAAI'90: 970-975, Boston, MA, 1990.
[Sadek 91a] Sadek M.D. Attitudes mentales et interaction rationnelle: vers une théorie formelle de la communication. Thèse de Doctorat Informatique, Université de Rennes I, France, 1991.
[Sadek 91b] Sadek M.D. Dialogue acts are rational plans. Proceedings of the ESCA/ETRW Workshop on the structure of multimodal dialogue, pages 1-29, Maratea, Italy, 1991.
[Sadek 92] Sadek M.D. A study in the logic of intention. Proceedings of the 3rd Conference on Principles of Knowledge Representation and Reasoning (KR'92), pages 462-473, Cambridge, MA, 1992.
[Sadek et al 95] Sadek M.D., Bretier P., Cadoret V., Cozannet A., Dupont P., Ferrieux A., & Panaget F. A cooperative spoken dialogue system based on a rational agent model: A first implementation on the AGS application. Proceedings of the ESCA/ETR Workshop on Spoken Dialogue Systems : Theories and Applications, Vigso, Denmark, 1995.
[Sadek et al 96a] Sadek M.D., Ferrieux A., Cozannet A., Bretier P., Panaget F., & Simonin J. Effective human-computer cooperative spoken dialogue: The AGS demonstrator. Proceedings of ICSLP'96, Philadelphia, 1996.
[Searle 69] Searle J.R. Speech Acts,
Cambridge University Press, 1969.